

WebSockets: a Comparison between Open-Source JVM Technologies

Introduction
This work aims to benchmark different WebSocket server technologies under progressive system overload. I will employ state-of-the-art, open-source, JVM web servers. In particular, I will focus on comparing two non-blocking models: Spring Webflux and Ktor. I will compare those systems also with Spring MVC, a thread-per-request engine.
I will also discuss about the Spring MVC WebSocket engine, highlighting the performance gap between these models.
The entire code of this experiments is here: https://github.com/Studiofarma/websocket-server-benchmark

A WebSocket server receives messages and notifies subscribers
(Image generated by the author with Dall-E 2)
WebSocket is a communication protocol that supplies two-way communication between client and server. It builds over HTTP, but it is in contrast with the client-server model, where a server cannot initiate a message transfer to a client. When a client opens a WebSocket, the server can push back messages at any time. With the standard HTTP commands, a server can only respond to a request from a client.
A WebSocket server keeps the communication channel open. It means that it can work as bridge between the clients. The clients can exchange messages each other, going through the server.
Methods
My primary goal is to think about a minimal system, making the side effects not relevant. Latency for example. I will adopt an echo server, in which both the server and client run on a local machine. This system forwards the messages back to the sending client. I will apply progressive system overload by increasing the number of concurrent users.
I will perform two different runs for each technology, using Apache JMeter.
The first run (from now on easy mode) is structered as follows:
- consider an initial chunk of 50 users connected to the echo server.
- keep increasing the connections in chunks of 200. Stop increasing at the maximum overload state, with 2000 concurrent users.
- keep the system in the maximum overload state for 3 minutes.
- start dropping out connections in chunks of 400 until 0. If any communication error happen, the existing connection gets closed. If any communication errors happen, the existing connection will be closed, kicking out the user from the echo server.
The second run (from now on hard mode) has the following structure:
- in a time range of 30 seconds, increase the number of active connections from 0 up to 12000
- keep the system in the maximum overload state for 1000 seconds.
- drop all the existing connections.
During the simulations, we care about:
- collect data describing the server response over time.
- the actual number of concurrent users over time. It may differ from the expected, since connection gets closed in case of errors.
- the percentage of requests processed with an error outcome.
- the number of exchanged bytes between the clients and the echo server.
- the server throughput (number of requests processed per second).
In every simulation I exchange a text sample of 5 kb, between the client and the server.
The system will have many clients exchanging messages with the server. In both easy and hard modes, we must pay attention to the frequency of messages from the same user. If the delay is too little, the server will be unable to deal with the overload.
To avoid it, I impose a delay to every user between consecutive messages. This also matches with a real-world-use case. I modeled the delay on a Gaussian distribution. It has a mean value of 5 sec. and standard deviation of 2 sec.
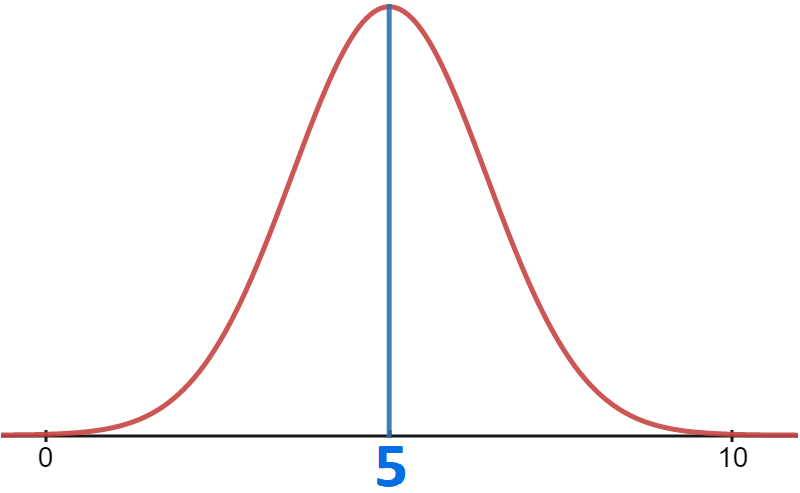
Gaussian distribution of the delay every user exchanges messages with. Image generated by the author.
With this model, we are sure that averagely each user exchanges a message with the server every 5 seconds.
With a 95% probability of waiting between 1 and 9 seconds before sending another message.
In the next lines, the code snippets for the Ktor and Webflux echo servers.
Ktor WebSocket server. Ktor version: 2.3.2 -see here).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
fun Application.configureSockets() {
install(WebSockets) {
pingPeriod = Duration.ofSeconds(10)
timeout = Duration.ofSeconds(15)
maxFrameSize = Long.MAX_VALUE
masking = false
}
routing {
webSocket("/ktor") {
for (frame in incoming) {
frame as? Frame.Text ?: continue
val userMessage = frame.readText()
send(userMessage)
}
}
}
}
WebFlux WebSocket server. Spring-Boot version: 2.6.7
1
2
3
4
5
6
7
8
9
10
11
12
@Component
public class ReactiveServerWebSocketHandler implements WebSocketHandler {
@Override
public @NotNull
Mono<Void> handle(@NotNull WebSocketSession session) {
return session.send(session.receive()
.map(WebSocketMessage::getPayloadAsText)
.map(session::textMessage)
);
}
}
Maximum overload of 2000 users (easy mode)
In this section I investigate how the systems responds when the maximum amount of concurrent users is reasonably small and the maximum overload state is reached progressively.

In the top panel the number of connected users during the run.
In the bottom panel, the comparison between the even-loop-based servers.
Image produced by the author using the software R.
For both the technologies, none of the incoming requests have an error outcome. Also, the amount of Kb exchanged per second and the server throughputs are very similar.
So far it seems that both technologies are pretty performant.
Let’s try to deeper investigate the results. The dotted lines represent the raw data of the server response over time. We can notice, some random peaks corresponding to fluctuations up to 20 ms.
It is difficult to understand how those peaks impact over the average values. Then I interpolated them using an R script, to better compare the two webservers. The solid lines on the graphic represent the results of this procedure.
Looking at those lines, it is clear that the average response time for Ktor is bit better then the one for WebFlux. This clarifies what is going on with the simulation parameters reported in the table. Indeed, the interpolated trends reflect the slightly better simulation results of Ktor. Most importantly, it indicates the low impact of the observed fluctuations. So far, both the technologies ensure stability during the run.
Maximum overload of 12000 users (hard mode)
In this case, the goal is to study what happens when:
- the time under maximum overload is longer
- the number of concurrent users is larger.
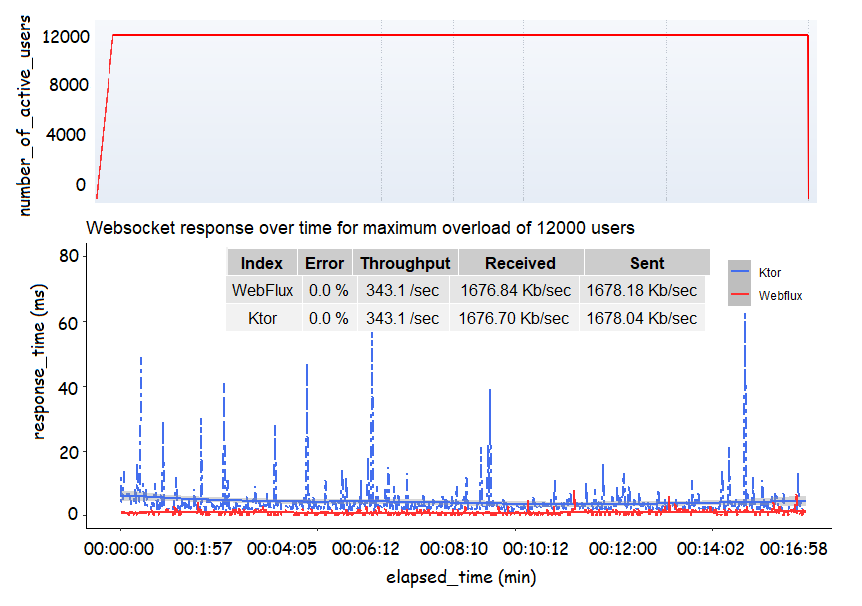
In the top panel the number of connected users during the run.
The bottom panel shows the comparison between the even-loop-based servers.
Image produced by the author using the software R.
The data in the table show that both the systems were able to process all the incoming requests. Also, the server throughputs and the amount of exchanged Kb/sec are very similar.
Anyway, the two systems present different behavior against this larger overload. This is in constrast to what experienced in the previous experiment. In this case Ktor shows larger fluctuations of the response time, while Webflux is stable. The interpolated trends also confirm this. Those trends show that WebFlux takes 6/7 ms less than Ktor, in average, to respond to the client. The shift between the two trends in this case is due to the impact of the observed instabilities.
Finally, it is worth to point out that the results presented rely on single runs. This means they lack statistical ensemble wideness. In other words, to give a better outcome about the best-performing, the number of simulations to carry out should be larger.
A Didactical Digression
It is interesting to do the same experiment, in the easy mode, with a thread-per-request model. I will build the same echo-server, this time using the WebSocket engine of Spring MVC.
Thread-per-request WebSocket server.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Component
public class ServerWebSocketHandler extends TextWebSocketHandler {
@Override
public void afterConnectionEstablished(WebSocketSession session) {
session.setTextMessageSizeLimit(20000000);
}
@Override
public void handleTextMessage(WebSocketSession callerSession, @NotNull TextMessage toForward) throws IOException {
String content = toForward.getPayload();
callerSession.sendMessage(new TextMessage(content));
}
}

In the top panel the number of connected users during the run.
In the bottom panel, response time in milleseconds, over time.
Image produced using raw data from JMeter.
In this case, the echo server can’t handle more than roughly 100 concurrent connections.
In particular, it presents an error percentage of around 12 % and a lower server throughput (15.4 /sec).
Also, looking at the server response over time, we notice a peak at every new connections chunk. The interpretation we can give on those results is intuitive. The trends clearly state that the thread-per-request server is unable to process a large amount of requests. Indeed, looking at the trends, we observe that the servers starts kicking out users. This happens every time the number of concurrent connections rise above around 100.
The Spring MVC implementation can’t handle a high number of concurrent requests. It is not optimal when the number of concurrent clients is high. An explanation is the fact that the Spring MVC thread pool has a finite size. Let us call this size S. In the thread-per-request model, a single thread will take care of the entire life-cycle of an incoming request. Let us say the duration of this lyfe-cycle is T. Given a number of concurrent requests greater than S, the system will run out of resources for the duration of T. This also explains why non-blocking models are preferable for those kind of applications.
Conclusion
I created an echo-server model to assess the performances of state-of-the-art non-blocking technologies. I stressed the systems under different loads, showcasing their high-level performances.
Ktor and Webflux demonstrated good stability under medium load conditions. Webflux resulted to be the most stable even in case of an heavy traffic volume.
Then, I performed the same test also for Spring MVC, that implements thread-per-request. This experiment showed that Spring MVC is not the right technology for this use-case. It was not able to grant stability for more then 100 concurrent connections.
The data show that the non-blocking model outperforms the thread-per-request, in this use-case.